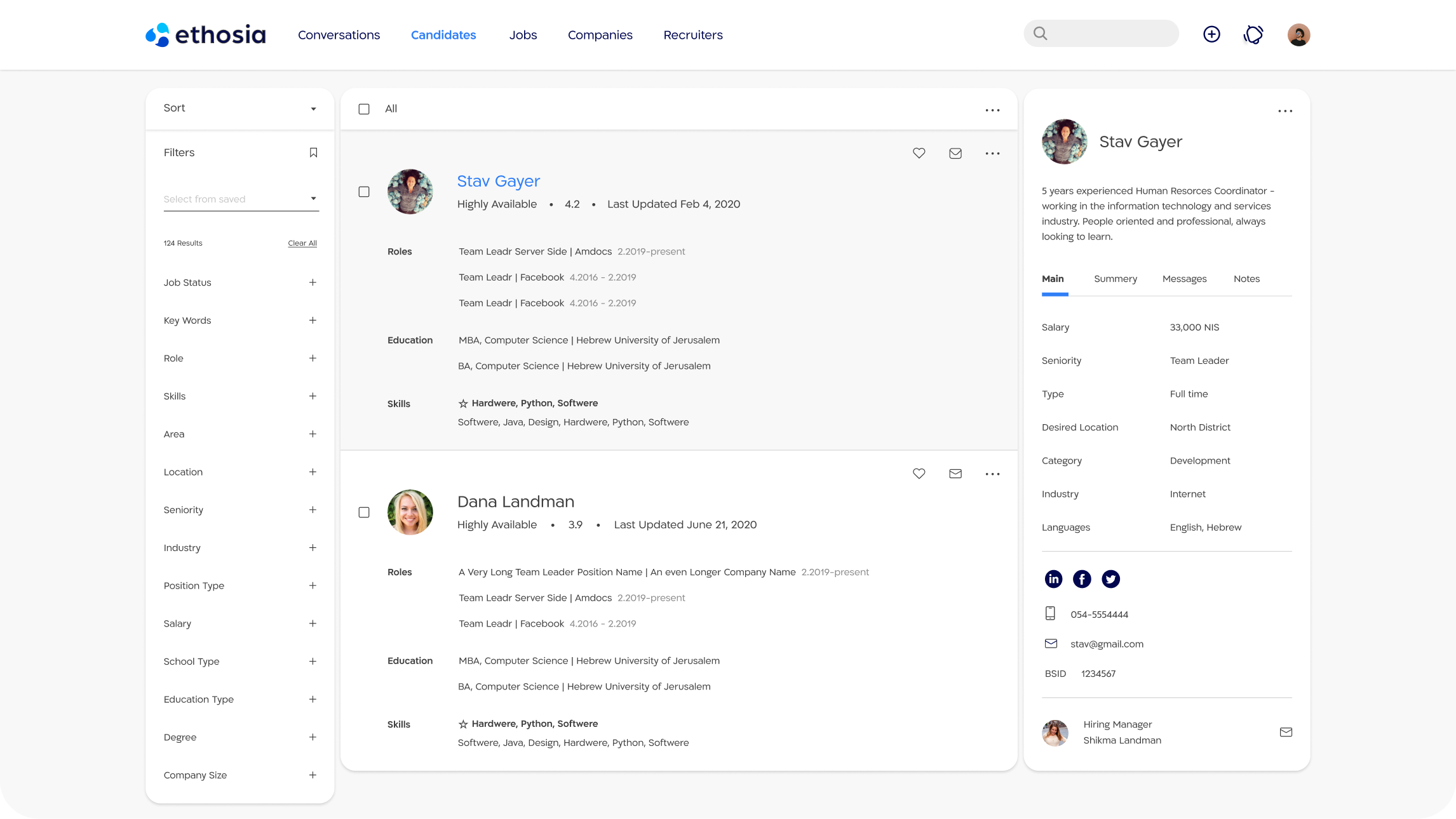
Responsibilities:• As a part of your role, you will work with a highly skilled engineering team in developing big data solution in order to make sure we continue delivering a leading AI solution.• Build large-scale batch and real-time data pipelines with data processing frameworks.• Use best practices in continuous integration and delivery.• You will deploy tools to capture, transform, analyze and store structured and unstructured data.
Requirements;• 5+ years of experience in Big data technologies.• Experience in Python – Big Advantage• Knowledge and experience using Clean Code SOLID practices – Big Advantage• Previous experience with Scrum – Advantage• A team player with the ability to work independently as well as within a team.• Good knowledge of Big Data querying tools, such as Pig, Hive, and Impala• Experience with integration of data from multiple data sources• Experience with NoSQL databases, such as HBase, Cassandra, MongoDB• Knowledge of various ETL techniques and frameworks, such as Flume• Experience with various messaging systems, such as Kafka or RabbitMQ• Good understanding of Lambda Architecture, along with its advantages and drawbacks• BS or MS in Computer Science or a related field – Advantage